2010-04-01
Abstract
Abhishek Singh and colleagues look at some of the more common methods of evading IDS/IPS detection and the ways in which solutions can counter these evasive techniques.
Copyright © 2010 Virus Bulletin
Use of an Intrusion Prevention System (IPS) and/or Intrusion Detection System (IDS) can be very effective in preventing and/or detecting the exploitation of certain classes of vulnerability over the network. This is most commonly achieved by matching patterns against the raw bytes sent over the network. This approach can be improved upon by breaking the raw bytes into constituent parts (protocol fields) before applying appropriate checks on the parsed data. The goal is to maximize both the confidence of the detection (match) and the resilience of the IDS/IPS systems to evasion.
There are many different types of protocol decoder in IDS/IPS systems. Some devices have protocol decoders which parse both the client and server messages, and have the capability of forwarding the traffic from one protocol to another. Some protocol decoders are limited to parsing the server messages, while others do not provide any forwarding of traffic to other layers. However, regardless of the type of protocol decoding used, detection can be evaded.
The structure and usage of each protocol is different. A protocol can accept an external input in various forms, and this can be a weakness. For example, in the case of HTTP, the web server www.microsoft.com can also be referred to as www.%6D%69%63%72%6F%73%6F%66%74%2E%63%6F%6D. While a strong signature can be developed to block attempts to exploit a given vulnerability, if the IPS/IDS itself does not take steps to prevent evasion, the signature will easily be bypassed.
In this article we look at some of the more common methods of evading IDS/IPS detection. Each section provides an overview of the problem, one or more concrete examples, and their respective solutions. A good IDS/IPS device should be able to address most, if not all, of the issues discussed in this article.
There are two types of protocol decoder: single directional and bidirectional. In general, a single-directional protocol decoder denotes that a command has ended by using the delimiter of the command, whereas a bidirectional protocol decoder uses both the delimiter of the command and the response code. If both directions of a session are not parsed (the state is not kept), it is possible that the system will apply signature logic incorrectly. This introduces the possibility of false positive detections.
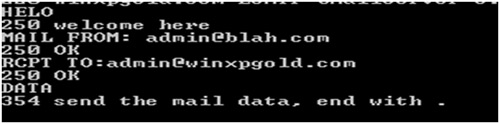
Let’s take the SMTP protocol as an example. SMTP stands for Simple Mail Transfer Protocol and is defined in RFC 5321 [1]. The normal flow of commands in SMTP is shown in Figure 1. The DATA is sent after the RCPT TO request.
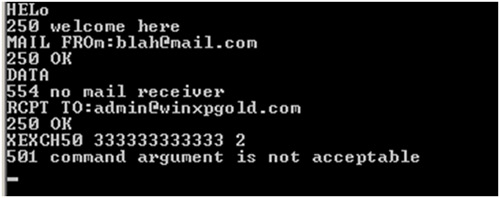
A single-directional protocol decoder will assume that the bytes that follow the DATA command are data and will allow them to pass through without checking for exploits. Figure 2 shows a situation in which the DATA command is issued before the RCPT TO request; the SMTP server will still be in a command state and will accept the command. The single-directional protocol decoder will be expecting the bytes that follow the DATA command to be data and will allow them to pass through. A bidirectional decoder, on the other hand, requires both the DATA command and the response code 354 to go to DATA state.
To reduce the possibility of false positives, it is recommended that an IDS/IPS system implement bidirectional protocol parsers.
Several protocols support the notion of using encryption to enable some form of privacy in support of security. The general problem with encryption is that it makes it difficult, if not impossible, for a man-in-the-middle (MiTM) implementation of IDS/IPS to interpret the raw bytes correctly. For example, upon starting a session, an RPC request is made for secure services whereby a secure context is established. This secure context might include a shared session key, sequence number, verification state, and so on. The secure context is used to form a secure connection between the client and the server. The client can send an encrypted RPC message to the server using the generated session key, with an optional authentication header. Upon receiving the message, the server decrypts it with the session key before processing the RPC. So exploit variants or encrypted exploits can be generated for many RPC vulnerabilities – such as MS08-067 (CVE-2008-4250), which was a propagation vector of the infamous Conficker worm. If the detection device cannot decrypt the traffic then the encrypted exploits can bypass detection.
As well as RPC, encrypted traffic can appear on port 80 for HTTPS connections, port 465 for SMTP, port 995 for POP3 [2] and port 993 for IMAP [3].
A detection device must be able to decrypt encrypted traffic and inspect it. In some IDS/IPS implementations, scanning encrypted traffic for exploits is possible by providing the IPS with decryption keys. The IPS first decrypts the traffic and then forwards the data to its signatures.
In many cases, protocols allow data to be encoded in various formats (encodings). These encodings are often published standards which can be used to transmit data. An IDS/IPS system acting as a MiTM should provide support for these various formats. If the IDS/IPS cannot return the encoded data to some ‘common/normal’ form, both the number and effectiveness of signatures will be impacted. Let’s consider a few encodings in HTTP, MIME and RPC.
The HTTP protocol is defined in RFC 2616 [4]. The URL field in HTTP can be used to exploit various vulnerabilities, hence many signatures are written to check the value of these fields. Signatures generally monitor the URL field in HTTP traffic.
The URL field can be encoded in many ways. The following are some of the encodings which are supported by various application web servers and can also be used by an attacker for encoding exploits:
Hex encoding: this is an RFC-compliant encoding in which an ASCII value is replaced by its hexadecimal value. For example, ‘A’ is represented as ‘%41’.
Double percentage encoding: this is based on normal hex encoding, the only difference being that the ‘%’ value is replaced by its hex value, i.e. ‘%25’. In this type of encoding, ‘A’ is represented as ‘%2541’.
Double nibble hex encoding: this is based on the standard hex encoding method, in which each nibble is hex encoded. For example, ‘A’ can be encoded as ‘%%34%31’. ‘%34’ resolves to 4 and ‘%31’ resolves to 1; thus, the encoding resolves to ‘A’.
Second nibble encoding: this differs from the first nibble encoding in that the second nibble value is encoded with a normal encoding. For example, ‘A’ is encoded as ‘%4%31’. ‘%31’ resolves to 1 and ‘%41’ resolves to ‘A’.
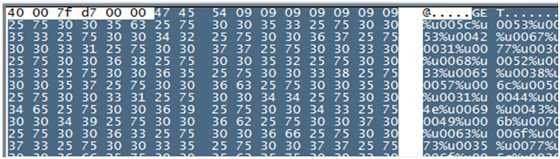
Microsoft %U encoding: the format for this encoding is ‘%UXXXX’, as shown in Figure 3. In this type of encoding, ‘%U’ is followed by four hexadecimal digits. For example, ‘a’ can be represented as ‘%U0041’.
Mismatch encoding: here, various types of encoding like hex, double nibble, second nibble and Microsoft %U encoding are combined to encode a single character. For example, in hex ‘U’ is encoded as ‘%55’. So, using mismatch encoding, ‘%U0041’ will be encoded as ‘%%550041’.
UTF-8 bare byte encoding: this is similar to UTF-8 encoding, the only difference being that UTF-8 byte sequences are not escaped with a percentage. Byte sequences are sent with the actual bytes.
Parameter evasion using POST and content encoding: if base64 is specified in the content encoding, parameter fields in the post request will be base64-encoded. Hence, the detection device will first have to decode the base64 and then check the stream for malicious content. Decoding of base64 can add extra overhead to the detection system.
As per RFC 2047 [5], there can be two types of MIME encoding: ‘B’ encoding, which is similar to base64 encoding, and ‘Q’ encoding, which is similar to quoted-printable content-transfer encoding. When a MIME message contains unknown RFC 2047 encoding, the detection device can either block the connection, assuming the encoding to be malformed, or it will decode the messages. RFC 2047 encodings provide a vector for evasion in the sense that the client can successfully decode messages in cases where the intrusion detection system is not able to decode them.
RFC 2045 [6] provides the content-transfer-encoding field, which allows the specification of an encoding type to enable eight-bit data to travel successfully through seven-bit transport mechanisms. Content-transfer encoding supports seven-bit, eight-bit, binary, quoted-printable and base64 encodings. The content-transfer-encoding field can be used to support other encodings as well, such as uuencode, mac-binhex40 and yenc. By encoding an exploit using an encoder that is supported by the email clients but not by the IPS, detection can be bypassed.
The RPC protocol [7] is used to perform client-server communication. The protocol makes use of the external data representation protocol which standardizes the representation of external data in remote communications. In RPC protocol, the client tries to access a remote computer, and the server is a machine that implements network remote procedures. The client makes a remote procedure call to the server and receives a reply which contains the result of the call. RPC supports various transports: TCP, HTTP, UDP and SMB. The RPC messages require unique specification of a procedure to call, matching of response messages to request messages, and authentication of caller to service and service to caller. The data in RPC protocol can be represented in big-endian, little-endian, Unicode, EBCDIC or ASCII strings. The exploit-specific signatures in RPC are prone to evasion.
Some of the evasions that are a result of various encodings are discussed in the following sections.
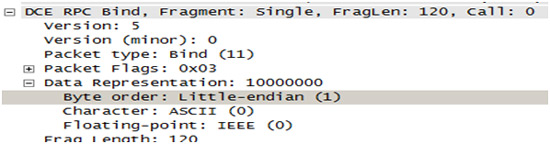
Endianness selection: in the header of every DCE RPC request there exists a data representation field in which the byte ordering, character set and floating-point representation are specified. Little-endian is used as default. However, even if the flag is changed to big-endian, the RPC request can be treated as a valid request. Based upon the value of the flag, an intrusion prevention system should be able to parse the packet. The detection device can be bypassed if it is not able to differentiate between the big-endian and little-endian packets.
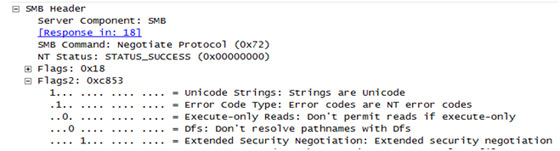
Unicode and non-Unicode evasion: the SMB header provides a two-byte Flag2 field which is used to determine whether the strings will be in Unicode or non-Unicode characters in the SMB header. Non-Unicode characters are used when the value of Flag2 is not set. Hence, all SMB commands, RPC functions and data will be in non-Unicode format. Based upon the Unicode or non-Unicode characters in the header, signatures should be able to check the incoming stream for exploits.
Where encoded data is concerned, the challenge is in making sure that the IDS/IPS system is capable of returning the encoded data to some normal form before signatures are applied. This allows the number of signatures required to address a given vulnerability to be kept to a minimum – for example, in the case of HTTP there will be at least eight signatures if the IPS does not provide support to decode data.
Several application-level protocols leverage the TCP/IP stack to ride on top of one another; failure of the IDS/IPS system to decompose raw bytes that use one or more protocols during an exchange generally results in missing attack vectors and, in the worst case, false negatives.
For example, the MS-RPCH (Remote Procedure Call over HTTP [8]) protocol tunnels RPC network traffic from an RPC client to an RPC server through a network agent referred to as an RPC over HTTP proxy. The protocol is applicable to network topologies where the use of HTTP- or HTTPS-based transport is necessary – for example, to traverse an application firewall where the application or computer systems communicating over the topology requires the use of the RPC protocol. This is used as an attack vector/evasive measure for DCOM [9] exploits such as MS03-026 and MS03-039 which arrive on ports 135, 139 and 445.
The protocol decoder should be able to forward the MS-RPCH traffic data from HTTP to the DCOM protocol decoder. Similarly, the SMTP headers and the HTTP traffic should be forwarded to the MIME protocol decoder.
In different applications a given protocol may be implemented in slightly different ways. As a result, protocol decoders for an IDS/IPS system need to relax the RFC compliance enforcement (i.e. implement it loosely) to account for the different implementations. Evasive methods appearing in protocols might not appear in all applications. The detection device should have application-specific anti-evasion measures.
The syntax for an HTTP request is as follows:
Method <space> URI <space> HTTP/Version <CRLF>
Some web servers accept a tab between the method and the URI, making requests such as those shown in Figure 6 valid.
If the protocol decoders of an intrusion prevention system only check for a space between the method and URI, detection can be evaded simply by sending a tab between the method and URI. Besides space and tab, some web servers also accept 0x09, 0x0b, 0x0c and 0x0d as valid separators between the method and URI.
Some web servers also accept %00 as a valid separator between the method and URI. It should be noted that NULL characters are used to denote the end of the string: the intrusion detection and prevention system stops once %00 is reached and allows the URI to pass through. Hence protocol decoders which parse the method and URI should accept %00 as a separator between the method and URI.
The syntax of HTTP v0.9 as per RFC 1945 [10] is:
GET <space> URI <CRLF.>
Only three parameters are sent in HTTP v0.9, and no headers are returned. If the HTTP v0.9 requests are not parsed correctly, then the HTTP signatures can be evaded simply by sending an exploit using HTTP v0.9 syntax.
Many web servers are flexible in accepting requests. For example, the request http://www.domain.com/index.html is similar to the request http://www.domain.com\index.html. So if the detection device only checks for forward slash patterns it can be evaded by sending a backward slash pattern.
Based on the implementation of CGI, it is often possible to use HEAD in place of POST. In some implementations, the method is ignored. Hence in many systems, an attacker can use the GET or the POST methods interchangeably in an exploit. If the detection device checks for a GET request followed by checking the URI for exploits, it can be evaded by using POST and the exploit URI pattern.
RFC 822, section 3.1.2, specifies that header fields are lines which are composed of a field name, followed by (‘:’), followed by a field body, and are terminated by CRLF. A separator is used to differentiate between the field names and the field body. Non-standard separators that are accepted by applications include a double colon, or the colon may be omitted altogether. If the MIME protocol decoders are not able to accept non-standard separators, they will not be able to separate the field name from the field body; signatures in turn will not be able to sanitize these fields and detection can be evaded.
RFC 2822 [11] states: ‘Strings of characters that include characters other than those allowed in atoms may be represented in a quoted string format, where the characters are surrounded by quote (DQUOTE, ASCII value 34) characters.’ Non-standard quoting includes quoting fields that should not be quoted, duplicating quotes, and the omission of leading or trailing quote characters from a string. Often, these non-standard quotings are accepted by applications but are not accepted by detection devices. Hence, if an exploit uses non-standard quotings, these may be accepted by the application, and the detection device will fail to properly parse and sanitize the traffic, allowing the exploit to go undetected.
Quoting RFC 822 [12], ‘A comment is a set of ASCII characters which is enclosed in matching parentheses and which is not within a quoted string. The comment construct permits message originators to add text which will be useful for human readers, but which will be ignored by the formal semantics. Comments should be retained while the message is subject to interpretation according to this standard. However, comments must NOT be included in other cases, such as during protocol exchanges with email servers.’ When an unexpected RFC 822 comment is present, the MIME message is either regarded as malformed and blocked, or the protocol decoder fails to interpret it correctly, which can lead to failure to detect an exploit.
It is possible for an attack to be spread over multiple packets. Protocols like MSTDS [13], Sun RPC, RPC and HTTP support fragmentation of packets while streaming. Since a server provides the capability of reassembling the disassembled packets, exploits can take advantage of this and spread across packets.
Taking the case of MSTDS, the protocol has the following structure:
Offset Size Description ----------- ------------- 0x0000 1 Type (0x01 for query) 0x0001 1 Status 0x0002 2 Length = X (big-endian) 0x0004 2 SPID (big-endian) 0x0006 1 Packet ID (big-endian) 0x0007 1 Window (unused, must be 0) 0x0008 X-8 Packet Data (Unicode)
To monitor for vulnerabilities, generally the Data field containing the name of stored procedures must be inspected. The Length field is a two-byte (16 bits) field in the header. If the TDS packet to be transmitted over the network is longer than the maximum 16-bit integer, then it must be split into smaller packet fragments. Each packet fragment, with the exception of the last, will contain the value 0x00 in the last packet indicator field to indicate that there are additional packet fragments to follow. On the receiving side, the full TDS packet payload is reassembled from these fragments.
In the case of HTTP, session splicing can be used to send an exploit across the packets. For example, one packet will contain ‘GET’, another will contain ‘/cgi’, another will contain ‘-bin’, and the last one will contain ‘HTTP/1.0’.
Similarly, fragmentation of RPC requests can occur. A normal piece of RPC data will contain a header and data, however, the entire RPC request can be split into multiple RPC requests. Since this is an application-level fragmentation, the IPS will have to reassemble the fragments of the packets. The IPS should have the capability of skipping the header of fragmented RPC packets and reassembling the RPC header and data. It should also check for malicious content in the packet.
In order for a detection device to prevent the spreading of an exploit across multiple packets, it is essential for it to assemble the packets in a session and then inspect them for exploits.
RFC provides specifications for a protocol. Evasion often occurs when an IDS/IPS fails to correctly decode a protocol into its constituent fields. As a result, it is possible that one of two outcomes occurs: a false positive and/or a false negative, depending on the nature of the decoding and signature logic. RFC-specific evasions fall under this category.
The URI http://www.microsoft.com/en/aaaaaaaaaaaaaaaaaaaaaa/../us/default.aspx descends into /en, then further descends into the aaaaaaaaaaaaaaaaaaaaaa directory, which may or may not exist. Following the next slash is a directory traversal, /.., which basically backs into /en/us. Hence the URL is similar to http://www.microsoft.com/en/us/ default.aspx and is accepted by the web server as a valid request, pointing to the same web page.
Sometimes IDS/IPS devices only check for the first xx bytes of a request. Thus, by sending a large enough number of ‘a’ characters, the rest of the submitted request will be moved outside of the IDS system scan. So if the malicious pattern is ‘/en/us’ and the IDS/IPS only checks for the first 1k bytes, ‘/en/’ followed by 2k of ‘aaa’, followed by ‘/../us’ will successfully avoid detection by the IDS/IPS.
In the RPC calling mechanism there is one bind request which can contain one UUID and one context ID. The server uses context ID to identify the UUID. Generally, IPS/IDS signatures check the UUID of vulnerable functions in the incoming stream and then parse the argument for malicious content. However, it is also possible for the server to receive multiple UUIDs and multiple context IDs for every single bind request. This is called multiple UUID bind and is a valid request. IPS rules that check for only one UUID and one context per bind request will allow the traffic to pass through, yet the multiple bind part of the UUID may be associated with a vulnerable function. The server will use the context ID and may make a call to the vulnerable function. To prevent multiple bind evasion, an IPS device should parse the bind request. If there are multiple binds and multiple context IDs, then it should keep track of vulnerable UUIDs and corresponding context IDs. If there is a vulnerable function call using that context ID, the IPS rules should monitor the functions for malicious content.
The path name \\\\\\\\\*SMBSOMESERVICE\C$ is treated in the same way as \\*SMBSOMESERVICE\C$. So, if a DCERPC signature is trying to block the path name, it can be evaded by adding \\\\\\\\. In order to prevent evasion, the IPS device must be able to check for the presence of extra ‘\’s in the path name.
A normal RPC call with a bind request contains a UUID with a context ID. The function opnum is called using that context ID. An opnum is an operation number or numeric identifier that is used to identify a specific RPC method or a method in an interface [14]. To open a new context for a different UUID over the same connection, the alter context DCERPC command [alter_ctx()] can be used. The alter context request leaves the previous context ‘on hold’. Alter context is required since, after binding to a specific interface, binding to another one over the same connection using bind () is not possible. However, the signature, which checks context ID, can be evaded by using alter_ctx().
In the first step of evasion, the normal UUID is associated with a context ID. The IDS or the signatures – which are checking the traffic on the basis of context ID – allow the traffic as normal traffic. Then an alternate context call is used to link the vulnerable UUID with the original context ID. This is followed by a call to a vulnerable function containing the vulnerable interface (UUID), which is made by using the context ID. Since the detection device tracks the context ID associated with the non-vulnerable UUID, protection can be evaded by using alter context.
In a normal RPC call, the arguments or the stub data generally appear after the opnum. However, it is possible for the opnum to be followed by the UUID, which is followed by the stub data. A detection device should be able to parse both scenarios. One of the methods to check such scenarios is to look up the value of the eighth bit in the packet flag. If the value of the eighth bit is set, the detection device should skip 16 bytes and check the start of the stub data.
The Ctx field appears at the end of a normal bind request. The RPC protocol also makes provision for authentication of the client to the server, and the authentication fields (such as auth type, auth level) can appear after the Num Ctx. These fields will not be present in the normal bind request. If a detection device treats the extra bytes as an extension of the context ID it will generate an error. This can be avoided by checking for the value of the auth length in the header. A non-zero value denotes the presence of extra bytes in the header.
The RPC handshake consists of a 20-byte secret number. This can be avoided by setting the idempotent flag in RPCv4 requests. If the flag is set, the 20-byte secret number can be avoided, also making it feasible to guess the request source. Since the flag allows the sending of the two requests as a single request, and if the IPS rules are dependent upon the handshake process, a signature can be evaded by setting the flag.
SMB commands ending with ‘ANDX’ can be chained. This leads to the sending, for example, of SMB_COM_TREE_CONNECT_ANDX + SMB_COM_OPEN_ANDX + SMB_COM_READ in a single SMB request. If a detection device checks for one SMB command in an SMB header, then it can be evaded by sending multiple chained commands. To prevent this, the detection device must check the value of the ‘AndXOffset’ field – if the value of this field is zero, then there will not be any more commands.
The AndXOffset field stores the next SMB command, and every AndX command has the offset in the packet to the following command. Hence the physical order does not have to match the logical order and an arranged packet can be built. The first command in the chain will be the first command in the packet. An intrusion detection device must have the ability to parse an SMB header with out-of-sequence command chaining; otherwise it will fail to calculate the number of SMB commands in the header.
It does not matter to Windows SMB implementation if there is more data than needed in a command. The AndXoffset contains the offset of the next command and it is possible to insert random data between the commands. A detection device must be able to parse it correctly.
There are a variety of methods that attackers can use to thwart IDS/IPS systems. We have discussed several of these. To recap, web servers support various encodings such as hex, double percentage, double nibble hex, second nibble, Microsoft %U, and mismatch encoding. Detection devices should be able to decipher these encodings. To prevent evasion in SMTP, it is recommended that the IDS/IPS implement a bidirectional protocol decoder – that is, the decoder should be able to parse both the client and the server messages correctly. MIME provides an option of various encodings, and the detection device should be able to decode the traffic correctly. MSRPCH is an evasion vector for DCOM-related vulnerabilities. A detection device should also be able to reassemble the packets and inspect them; otherwise an attack can be spread over packets. The RPC protocol is also prone to evasion. RPC provides various options of sending commands such as Unicode, non-Unicode, big-endian and little-endian format. A detection device also should be able to decipher these formats.
In this article we have looked at some of the commonly occurring evasion methods. For effective protection it is vital for intrusion prevention and detection systems to have anti-evasion measures.
The authors would like to express their gratitude and thanks to Jimmy Kuo for his feedback on the article and to Patrick Nolan.
[15] A look at whisker’s anti-IDS tactics. http://www.wiretrip.net/rfp/txt/whiskerids.html.
[16] Multiple vendor MIME field multiple occurrence issue. http://research.corsaire.com/advisories/c030804-002.txt.
[17] Multiple vendor MIME field whitespace issue. http://research.corsaire.com/advisories/c030804-003.txt.
[18] Multiple vendor MIME field quoting issue. http://research.corsaire.com/advisories/c030804-004.txt.
[19] Multiple vendor MIME Content-Transfer-Encoding mechanism issue. http://research.corsaire.com/advisories/c030804-005.txt.
[20] Multiple vendor MIME RFC822 comment issue. http://research.corsaire.com/advisories/c030804-009.txt.
[22] Caswell, B.; Moore, H.D. Thermoptic Camouflage Total IDS Evasions. http://www.blackhat.com/presentations/bh-usa-06/BH-US-06-Caswell.pdf.
[23] Legiment Techniques of IPS/IPS evasions. http://null.co.in/papers/legiment_ajit.pdf.
[24] HTTP IDS Evasion Revisited. http://docs.idsresearch.org/http_ids_evasions.pdf.