2010-08-01
Abstract
Marius Tibeica describes a solution for protection at browser level by providing an automated method of detecting phishing based on the tag structure of the HTML.
Copyright © 2010 Virus Bulletin
Phishing can no longer be considered a new and emerging phenomenon that is easy to detect with basic filters. Fake websites impersonating national or global institutions are easily created using advanced methods that trick the traditional detection filters (e.g. using JavaScript encoding, images that replace words, Flash objects, frames, and even customized website distribution using GeoIP). What’s more, the number of targeted phishing attacks has increased in recent months, as information about potential victims can now easily be accessed on social networks or blogs (targeted phishing is phishing that contains personal information in order to appear genuine). Bearing this in mind, this article will offer a possible solution for protection at browser level by providing an automated method for detecting phishing. The proposed method is based on the structure of the HTML and not the visible content. Our algorithm consists of creating signatures based on the tag structure of the HTML and comparing them with the signatures of web pages that we want to protect, as well as with recent phishing templates.
Most anti-phishing technologies check the URL against a list of known phishing web pages (a blacklist), most of which are available on the Internet. The problem with blacklists is that, in most cases, the time frame needed for a URL to become blacklisted worldwide overlaps with the time in which the phishing attack is most successful [1], [2].
Also, scanning URLs in the cloud in order to feed fresh phishing websites to blacklists can cause several detection issues including:
A variable time frame from the moment at which a new phishing website is launched until the moment it is added to a blacklist.
A variable length of time for hacked legitimate websites containing phishing pages to be removed from the blacklists once the phishing pages have been deleted from the legitimate domains.
Different content served to visitors depending on their geographical location.
Redirects or redirect loops.
Web pages which require a login in order to view the bulk of the content.
Beside traditional blacklists, the BitDefender approach (presented in [3]) consists of a method that detects the similarity of two web pages using the Jaccard distance (Jaccard similarity uses word sets from the comparison instances to evaluate similarity). This offers great protection against phishing web pages that mimic legitimate web-banking pages, but is not so efficient when encountering phishing sites that have little similarity to their legitimate correspondent or which contain just a few words – this is not enough for a confident content-based detection.
Our method consists of creating and maintaining a database of website templates extracted from legitimate institutions (banks, webmail providers, social networking websites and any other institution that requires phishing protection) and new and emerging phishing pages, together with a mathematical distance capable of measuring the similarity between new extracted templates and those in our database.
We will now explain how we created the specified templates, how we constructed our database, and also explore several distances in order to find the most suitable one for our purpose.
Each HTML tag has a specific function, whether it is used in rendering the layout (e.g. <b>, <center>, <h1>), creating links (<a>), images, tables and lists, styles, programming, breakers, forms or comments. To conduct our experiment we created multiple sets of tags that have the same function, and one different set for all the words that are not tags. For each HTML tag, we identified the set to which it belonged and added a corresponding marker (a letter) to a signature. We define a summary signature as the tag structure extracted using this method from any HTML document.
Table 1 contains an example of a sample web page and the generated summary signature.
| HTML | Summary |
|---|---|
| <html> <head> <title> A Small Hello </title> </head> <body> <h1> Hello World </h1> </body> </html> | [O] Other start [I] Info start [I] Info start [WWW] 3 words [i] Info end [i] Info end [O] Other start [F] Format start [WW] 2 words [f] Format end [o] Other end [o] Other end |
Table 1. Summary generation.
The resulting summary signature of the ‘Hello world’ example is: OIIWWWiiOFWWfoo.
The score obtained by the string distance between two signatures represents the similarity between two summaries.
To choose the distance between two summaries we had to take into account the following factors, in the following order:
The false positive (FP) rate, which should be kept as low as possible.
The distance, which should not be affected by tag soup – a method we estimate phishers use quite often.
Speed – we should be able to calculate a great number of distances between the analysed HTML and all the stored signatures in real time.
The false negative rate, which should also be kept as low as possible.
The candidates for the best distance were: the Levenshtein distance, the Damerau distance, the Hamming distance and the Jaccard distance. (The Levenshtein edit distance is a measure of similarity between two strings, which represents the number of deletions, insertions or substitutions required to transform one string into another. The Damerau edit distance is identical to the Levenshtein edit distance, except that it also allows the operation of transposing (swapping) two adjacent characters at no cost. The Hamming distance is the number of places in which two strings differ.)
To decide which edit distance to choose, we conducted an experiment as described below.
We created summaries from three groups:
50 HTMLs from the web-banking pages that we want to protect (the most phished brands according to both anti-phishing.org and our internal statistics)
24,199 other legitimate HTMLs
5,612 phishing HTMLs from 12 consecutive days.
We considered that a signature x would match a signature y with a threshold T if:
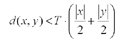
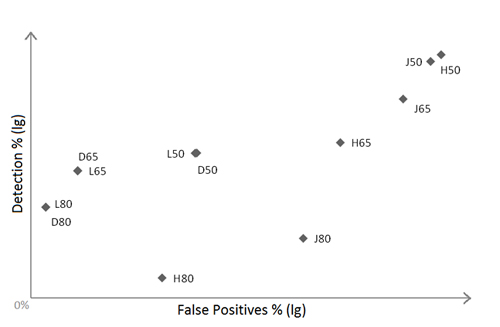
We then measured how many of the phishing and legitimate summaries were matched by the protected summaries, with three thresholds: 0.5, 0.65 and 0.8. The detection and FP rates are presented in Table 2.
| D% 0.5 | FP% 0.5 | D% 0.65 | FP% 0.65 | D% 0.8 | FP% 0.8 | |
|---|---|---|---|---|---|---|
| Lev | 7.03 | 0.1116 | 5.40 | 0.0083 | 3.15 | 0.0041 |
| Dam | 7.05 | 0.1157 | 5.42 | 0.0083 | 3.15 | 0.0041 |
| Ham | 27.51 | 20.41 | 8.23 | 2.77 | 1.10 | 0.0537 |
| Jac | 30.40 | 25.76 | 15.73 | 11.12 | 1.98 | 1.22 |
Table 2. Detection (D) and false positive (FP) rate.
The results are easy to interpret on the following graphic (on a logarithmic scale):
We observed that the Hamming and Jaccard distances have unacceptable FP rates.
Levenshtein and Damerau return almost the same result, which is understandable considering the fact that the algorithms are fairly similar. By increasing the threshold we get lower detection, but also a lower FP rate.
The best compromise seems to be either the Levenshtein or the Damerau distance with a threshold of 0.65, but this will be determined by conducting a more accurate experiment.
Analysis of our available phishing data shows that the number of phishing kits is relatively small compared to the total number of phishing websites published during a month. (A phishing kit is a collection of tools assembled to make it easy for people to launch a phishing exploit. The kit includes templates of phishing web pages.) By using the summary signatures of new phishing pages for detection, alongside the summaries of the web-banking pages, the proactive detection rate increases consistently.
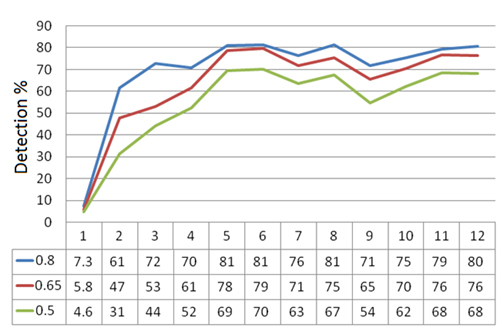
In our second experiment we used as a test corpus the same data as in the first experiment, but this time we not only used the summaries of the protected institutions for detection, but also the summaries of phishing pages from the preceding weeks.
We considered the same three thresholds (0.5, 0.65 and 0.8), and the Levenshtein distance (the Damerau distance has the same results).
We obtained the following results:
It can be seen that using the phishing summaries beside the legitimate summaries greatly increases the proactive detection rate.
We also compared the same legitimate HTMLs with the summary signatures of the protected banks and of all the phishing HTMLs to determine the FP rate (Table 3).
We can conclude that each of the thresholds has its own advantages. The choice can be made with a small compromise: either the detection rate is slightly reduced or the FP rate is slightly increased.
Computing the Levenshtein distance between two strings is too time consuming to be used to check whether a summary is matched by a large number of stored summaries in real time, which means that we need some improvements. (The Levenshtein edit distance is found in O(mn) time (where m and n are the length of the measured strings).
As a first optimization, we use this filter only if the HTML contains login information. However, this optimization alone is not sufficient, because users tend to browse several websites that require logging in each day.
For each signature, we compute each tag group’s number of occurrences. When comparing two signatures, we calculate the sum of the number of tag groups that differ (for example, one summary might have more format tags and fewer table tags than another). A Levenshtein distance between the two signatures cannot be smaller than twice the sum. We call this the minimum difference, which can be computed fairly quickly. (The minimum distance is calculated in O(m+n) time, which is one order less than the Levenshtein computing time.)
For one signature to match another, the distance between them needs to be smaller than:
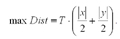
If the computed minimum distance is higher than the maximum distance for a match, it is not necessary to go on and compute the Levenshtein distance, as a match cannot occur. Our data indicates that this optimization eliminates 95% of the distances that have to be computed.
The proposed filter is easy to train, its sole prerequisite being the fact that the phishing web pages used to generate signatures should be genuine ones (not 404 or other server error pages).
Since this filter detects the similarity between legitimate websites and the fake ones, it is obvious that it will detect the legitimate websites as being 100% similar to themselves, which means that these URLs must be whitelisted.
The detection capabilities extend beyond the initial protected pages if summary signatures of available phishing web pages are used, but this can also cause future problems if the legitimate phished pages are not whitelisted.
The method showed good results both in lab testing and market testing, covering the gaps in detection caused by the evolution of phishing and the downside of blacklists.
The accuracy of the proposed method can be significantly increased if we add CSS, keywords, relevant information inside the scripts, or other information to the summary signature.
This paper is part of the bachelor diploma project entitled Proactively Fighting New Generations of Phishing. The work benefited from the help of BitDefender.
[2] Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.F.; Hong, J.; Zhang, C. An Empirical Analysis of Phishing Blacklists. CEAS 2009.
[4] Damerau, F.J. A technique for computer detection and correction of spelling errors. Communications of the ACM, 3, 7, 171–176, March 1964.
[5] Hamming, R.W. Error Detecting and Error Correcting Codes. Bell System Tech Journal, 9, 147–160, April 1950.